
输入脑海中想要实现的视频场景描述,就能在短时间内获得栩栩如生的视频呈现。这样的“神奇”如今在视频大模型中就成为了现实。
日前,阿里云旗下视觉生成基座模型万相2.1(Wan)宣布开源,同时支持文生视频和图生视频任务。如果通俗点理解这个大模型的厉害之处,就是首先在文生视频领域做到了性能的领先。其中14B万相模型在指令遵循、复杂运动生成、物理建模、文字视频生成等方面表现突出,在权威评测集VBench中,万相2.1的成绩大幅超越Sora、Luma、Pika等国内外模型,稳居榜首位置。其次和Deepseek有异曲同工之妙的是,Deepseek实现了大模型训练成本的大幅降低,万相则是将视频大模型部署推理门槛降到了“消费级”:阿里云方面表示只要消费级显卡就能运行,也就是说如果家里的显卡还过得去,在家的电脑也能部署体验。
“性能出众,平易近人。”的万相2.1一时间成为了为视频大模型带来了“Deepseek时刻”。
面对视频大模型开源带来的新一波热潮,南方+记者独家采访了阿里通义万相产品负责人张宁奕,就视频大模型的技术发展和未来趋势展开了探讨。
“事实上,我们在模型结构、预训练策略以及推理等全链路进行了创新。”在谈到万相2.1如何能够做到“实现高性能与低硬件需求”这样的提升时,张宁奕认为是通过大模型底层开始的全面创新,带来的技术进步。“例如,在模型架构优化上:通过「3D VAE模块」实现时空压缩(时域4倍、空域64倍,总计256倍压缩率),显著降低显存占用;采用「分块特征缓存策略」支持长视频生成,消费级显卡(如RTX 4090)即可运行1.3B模型。”
从万相2.1的进化中不难看出,作为一项全新的技术,即使目前已经处于“百模大战”的格局,同样具有弯道超车的机会。
“从模型表现来看,万相正在成为视频生成领域的新标杆。”据张宁奕介绍,在权威评测VBench的16项指标中,万相的综合得分稳居第一,尤其在物理模拟(如流体、碰撞)和复杂运动(体操、击剑)生成上超越多数开源模型,其中,1.3B模型仅需8.2GB显存生成480P视频,对比同类模型显存需求降低30%,处于“消费级友好型视频模型”前沿。“社区的反馈更加直观,我们开源两天不到,就登上了Hugging Face热度榜单第三,大量开发者在部署和体验万相模型。”
Deepseek在火出圈后,“服务器忙”成为了大家对其的“第一印象”。而作为对算力要求更高的视频大模型而言,也提出了更高的要求。张宁奕表示,为应对GPU算力的指数级增长需求,尤其是正在爆发的推理市场,阿里云已全面重构底层硬件、计算、存储、网络、数据库、大数据,并与AI场景有机适配、融合,加速模型的开发和应用,打造一个AI时代的最强AI基建。据张宁奕透露,阿里云已经打造出一套稳定和高效的AI基础设施,连续训练有效时长大于99%,模型算力利用率提升20%以上。
值得留意的是,与Deepseek同走“开源路线”,也是万相大模型迅速出圈的重要原因。张宁奕就表示,此次开源的14B/1.3B双模型,可以进一步和学术界探索长视频生成技术,同时与产业界一起推动大模型技术在千行百业的应用。“阿里云最早提出MaaS(模型即服务)理念的科技公司,阿里云魔搭社区为AI开发者提供模型体验、下载、调优、训练、推理、部署等一站式服务。截至目前,魔搭社区已上架千问Qwen、万相Wan、DeepSeek-R1、Llama等国内外知名模型,服务超过1000万开发者。”
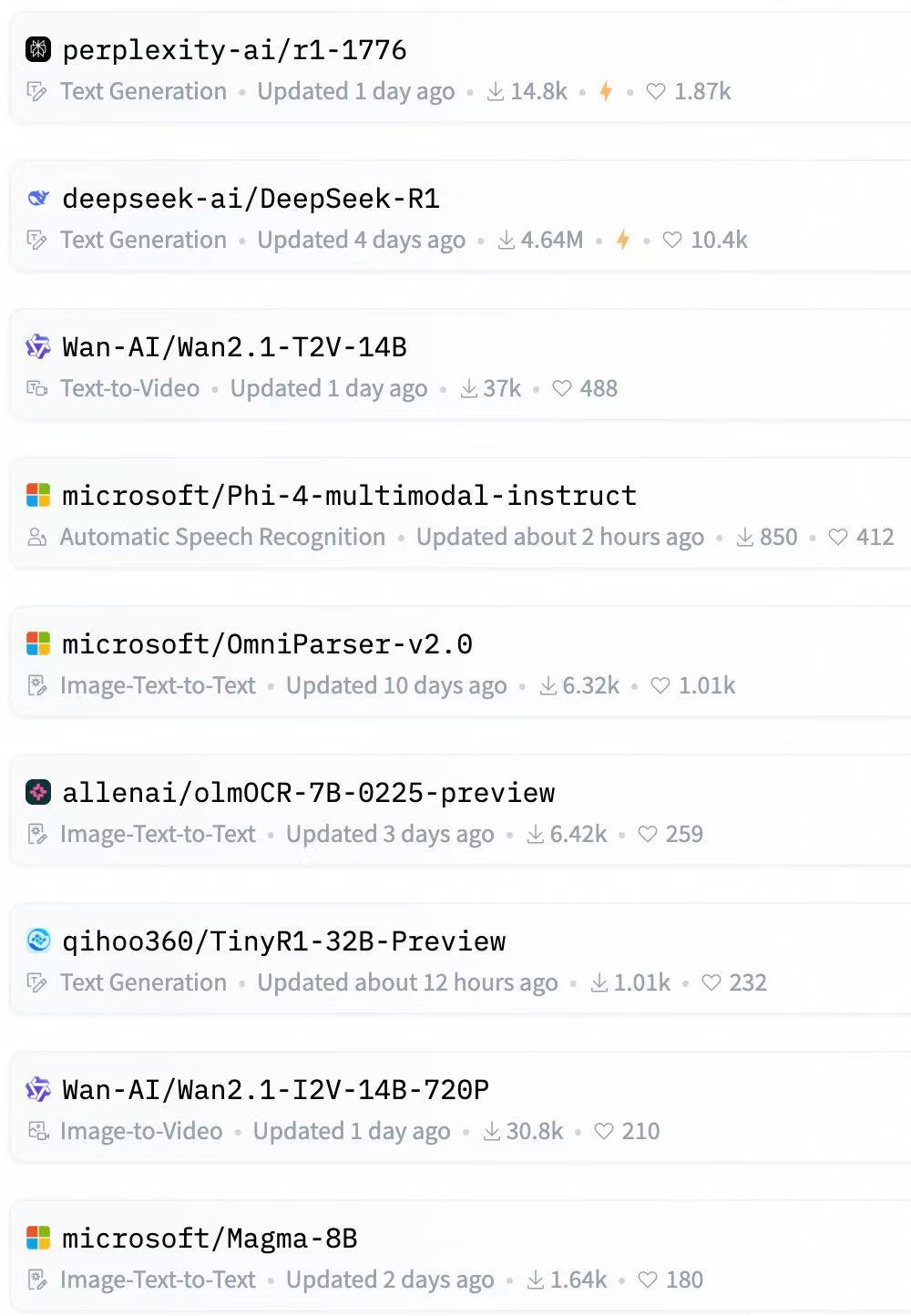
开源两天不到,万相就登上HuggingFace热度榜单第三
在业内人士看来,开源的路径将大模型的应用门槛进一步降低,而如今视频大模型的到来,将会带来比此前Deepseek只能实现文字对话要大得多的应用价值。
“过去两年,各个模态的大模型性能取得了巨大提升,但要实现大规模落地,将高效率的模型开源是重要途径。我们希望万相大模型能让个人创作者、中小团队无需专业设备/团队即可生成影视级内容,推动“创意普惠”。”张宁奕表示,随着模型能力的进一步提升,未来视频生成大模型将有力推动影视与动画、电商与营销、教育与科普:将抽象概念(如物理规律、生物生长)动态可视化、游戏开发等领域的发展,用大模型快速生成预演镜头,辅助分镜设计,一键生成商品展示视频等将成为现实。
对于大模型进入视频时代后将带来的变革和影响,张宁奕坦言将会推动内容创作领域的彻底变革。“未来普通人可以通过自然语言生成短视频,冲击传统UGC/PGC边界;另外,还将催生更丰富的个性化体验,可以通过创作者+协作模型共同成长来获取优质内容,沉淀一套更定制化的优质内容生产模型。从技术角度看,大模型未来仍将持续创新,同时会朝着多模态融合的方向发展,例如视频与语音/3D模型联动(如生成带旁白的教学视频)。”
采写:南方+记者 叶丹
剪辑:南方+记者 龙达洋